简单分析preg_replace源码
前几天在p神的文章经典写配置漏洞与几种变形中看到了一个preg_replace的trick
看了下这个解法的提出者l3m0n师傅也没有给出具体的原理,只是猜测preg_replace做了转义的处理
但是preg_replace为什么要转义呢?翻看preg_replace的文档可以看到preg_replace的第二个参数replacement有两个特性:
replacement中可以包含后向引用
\\n或$n,语法上首选后者。 每个 这样的引用将被匹配到的第n个捕获子组捕获到的文本替换。 n 可以是0-99,\\0和$0代表完整的模式匹配文本。 捕获子组的序号计数方式为:代表捕获子组的左括号从左到右, 从1开始数
如果要在replacement 中使用反斜线,必须使用4个(“
\\\\”,译注:因为这首先是php的字符串,经过转义后,是两个,再经过 正则表达式引擎后才被认为是一个原文反斜线)
猜测这个trick与preg_replace的这两个特性有关,具体的原因还需要看看源码
环境搭建
windows下调试php需要用到php-sdk-binary-tools,具体操作可以参见官方文档
编译的时候需要将文档中的configure --disable-all --enable-cli --enable-$remains换为configure --enable-debug --enable-phpdbg
使用vscode调试编译好的php可以参见PHP源码调试分析
另外一开始使用vs2017编译时会报错,换成vs2019就行了…
测试的php代码
1 |
|
preg_replace实现
preg_replace代码位于ext/pcre/php_pcre.c中的php_pcre_replace_impl
先不贴代码,说下preg_replace的工作流程:
- 把
bbbaaab拆成bbbaaa和b - 把
bbbaaa变成bbb\\'(我们关心的部分) - 在
bbb\\'后面加上b
第二部分分为两步,主要是两个及其相似的while循环
- 计算替换后原有字符串的长度,比如这里
bbbaaa变成bbb\\',new_len就会是6
1 | while (walk < replace_end) |
- 真正的替换
1 | while (walk < replace_end) |
答案也很明显了,以第二个while循环为例:
walk用于遍历replacementwalk_last记录当前字符的上一个字符- 当
walk是'\\'或'$'时会触发反向引用
1 | //反向引用 |
- 连续两个
\\就会吞掉一个\\,并且把walk_last置为'\0'
1 | if ('\\' == *walk || '$' == *walk) |
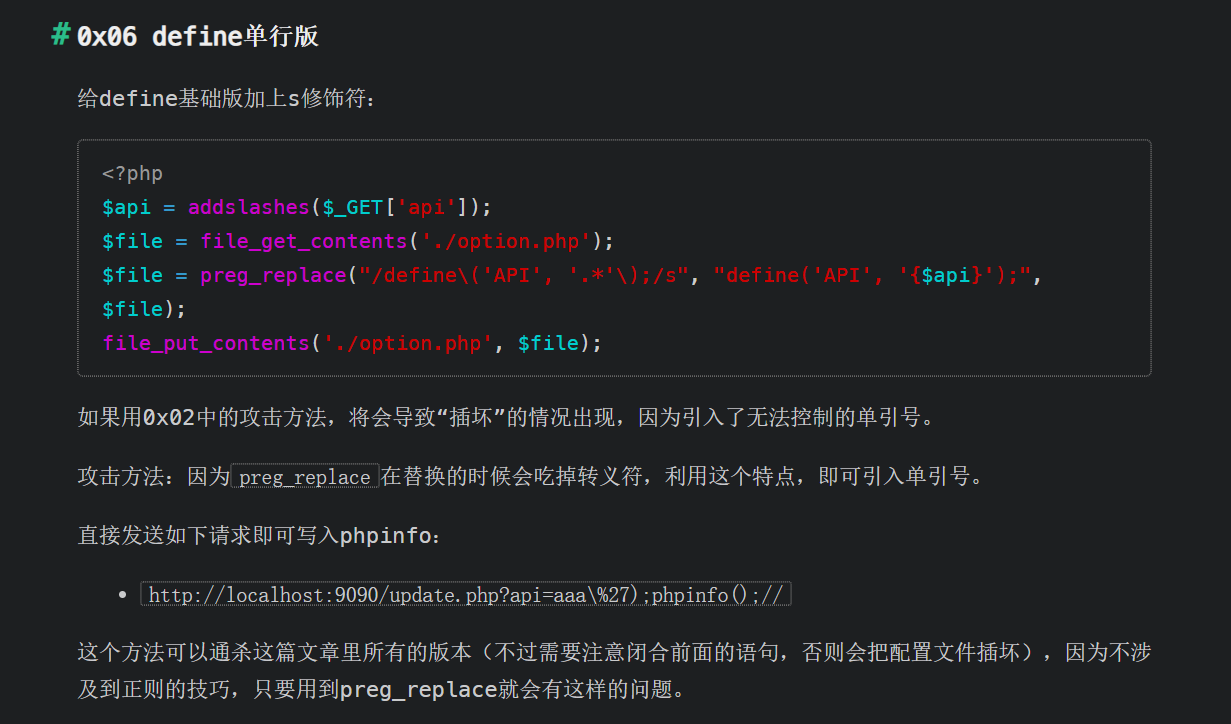
测试代码中的$replacement经过addslashes后用c字符串表示是"\\\\\\'",第二个\\会被continue掉,因为这时walk_last变为了'\0'所以第三个\\就被保留了下来。直接输出或者写入到配置文件中就变成了\\',逃逸出了一个单引号
之所以有这样的特性就是为了区分反斜线和反向引用,也可以算是一种转义,所以l3m0n师傅的猜测可以说是正确的